import random import string import itertools from secret import FLAG key = ''.join(random.choices(string.ascii_letters + string.digits, k=16)) cipher = bytes([ord(m)^ord(k) for m, k inzip(FLAG, itertools.cycle(key))]) print(cipher) #cipher=*
from given import cipher key=b'89qEUTFDJaeColtK' s="" for i inrange(len(cipher)): s+=chr(key[i%len(key)]^cipher[i]) print(s) ''' Symmetry in art is when the elements of a painting or drawing balance each other out. This could be the objects themselves, but it can also relate to colors and other compositional techniques. You may not realize it, but your brain is busy working behind the scenes to seek out symmetry when you look at a painting. There are several reasons for this. The first is that we're hard-wired to look for it. Our ancient ancestors may not have had a name for it, but they knew that their own bodies were basically symmetrical, as were those of potential predators or prey. Therefore, this came in handy whether choosing a mate, catching dinner or avoiding being on the menu of a snarling, hungry pack of wolves or bears! Take a look at your face in the mirror and imagine a line straight down the middle. You'll see both sides of your face are pretty symmetrical. This is known as bilateral symmetry and it's where both sides either side of this dividing line appear more or less the same. So here is the flag: hgame{X0r_i5-a_uS3fU1+4nd$fUNny_C1pH3r} '''
Tqh ufso mnfcyh eaikauh kdkoht qpk aiud zkhc xpkkranc uayfi kfieh 2003, oqh xpkkranc fk "qypth{hp5d_s0n_szi^3ic&qh11a_}",Dai'o sanyho oa pcc oqh dhpn po oqh hic.
果然,破译后有了大发现:最后的一句话内容是to add the year at the end,那么后面应该加个$2021$,最后提交内容是
hgame{ea5y_f0r_fun^3nd&he11o_2021},果然对了。
4.signin
先看一下题目
1 2 3 4 5 6 7 8 9 10
from libnum import * from Crypto.Util import number from secret import FLAG m = s2n(FLAG) a = number.getPrime(1024) p = number.getPrime(1024) c = a ** p * m % p print("a = {}".format(a)) print("p = {}".format(p)) print("c = {}".format(c))
题目最后给出了$a,p,c$的值。其中$a^pm\equiv c\pmod p$。
根据费马小定理可知,$a^p\equiv a\pmod p$,因此原式就是$am\equiv c \pmod p$,故$a^{-1}c\equiv m \pmod p$,我们只需要用内置函数求个逆元就结束了。
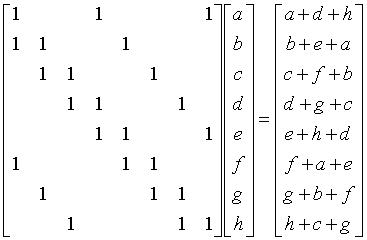
defsolve(y,n,l,r): y^^=n M,v=[],[] for i inrange(64): M.append([0]*64) v.append([0]) for i inrange(64): M[i][i],M[i][(i-l)%64],M[i][(i+r)%64]=1,1,1 M=matrix(GF(2),M) for i inrange(64): v[i]=y&1 y>>=1 v=vector(GF(2),v) M=M^-1 G=vector(ZZ,M*v) s=0 for i inrange(64): s+=(G[i]<<i) print(hex(s)) #------main-below------# Y=[15789597796041222200,8279663441787235887,9666438290109535850,10529571502219113153,8020289479524135048,10914636017953100490,4622436850708129231] N=[14750142427529922,2802568775308984,15697145971486341,9110411034859362,4092084344173014,2242282628961085,10750832281632461] L=[3,9,5,13,64-16,7,5] R=[7,4,2,6,8,5,2] for i inrange(7): solve(Y[i],N[i],L[i],R[i]) ''' 0x6867616d657b6c 0x316e6530725f61 0x31676562723026 0x697340316d706f 0x7231306e315e31 0x6e246372797074 0x6f7d '''